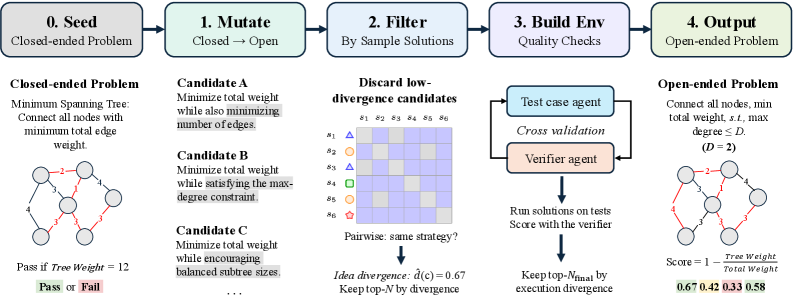
Accessible
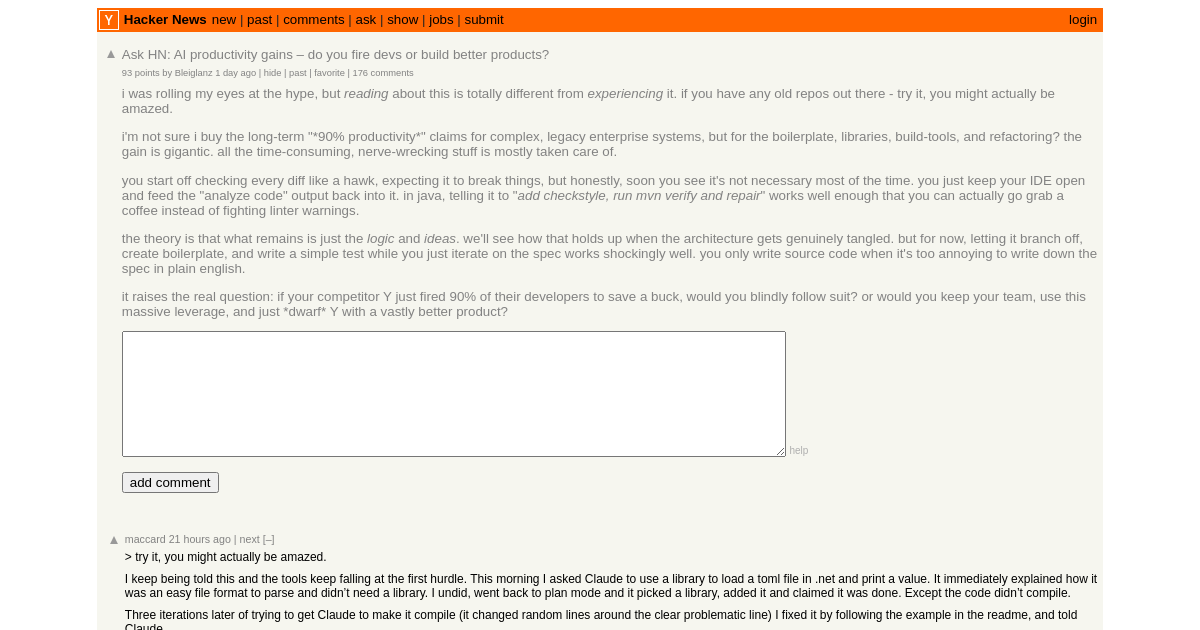
Quoting Kenton Varda
Kenton Varda (Cloudflare) banned AI-generated PR descriptions from his team after finding they reliably described what the code does while omitting why — the higher-level framing reviewers actually need. This is a sharp practitioner observation: AI excels at summarizing visible structure but consistently fails at articulating the motivation, tradeoffs, and context that make code reviews meaningful. A useful corrective to uncritical adoption of AI-assisted commit hygiene.
Takeaways
- AI-generated commit and PR messages optimize for describing code mechanics, not communicating intent — which is exactly backwards for reviewers.
- The higher-level framing needed to understand a change is often not recoverable from the diff alone, making it irreplaceable by AI summarization.
- Teams should consider explicit norms distinguishing where AI writing assistance adds value versus where it degrades communication quality.