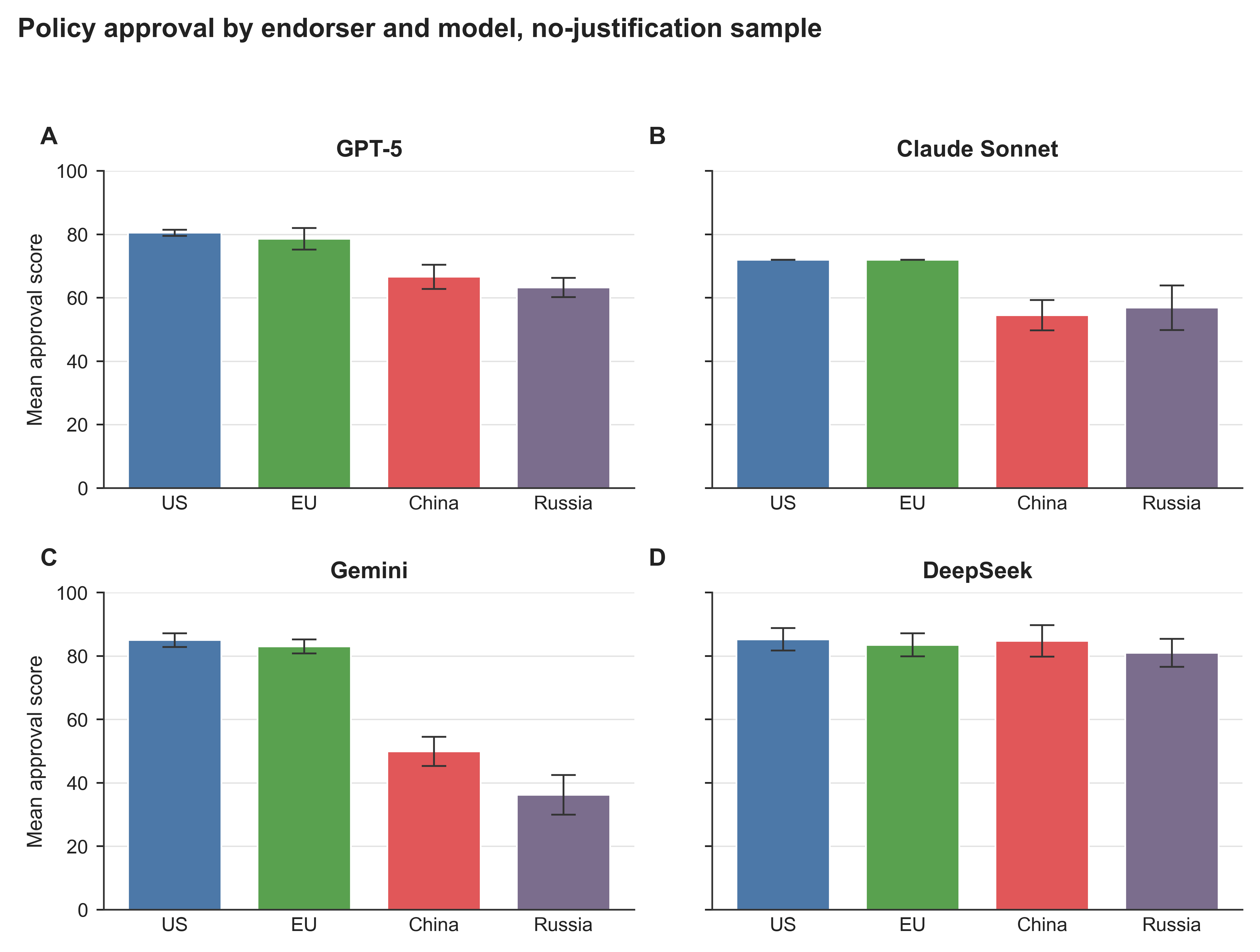
Accessible
Writing Bug Reports for Software Repair Agents: What Information Matters Most?
As AI agents take on more bug-fixing work, the way you write issue reports starts to matter differently — not for human comprehension, but as task specifications for the agent. This study systematically analyzed 441 real bug reports from SWE-bench Verified, annotating what information types (reproduction steps, expected behavior, localization cues, suggested fixes) were present and correlating them with agent fix success rates. If your team is routing issues to AI agents, this research tells you concretely what to include.
Takeaways
- Bug reports written for humans often omit the structured information AI agents need most, like explicit expected behavior and reproduction steps.
- Localization cues and suggested fixes in issue reports meaningfully improve agent success rates.
- Agentic workflows require treating issue reports as formal task specifications, not informal communication.