Accessible
Geopolitical alignment: Endorsement effects in large language models
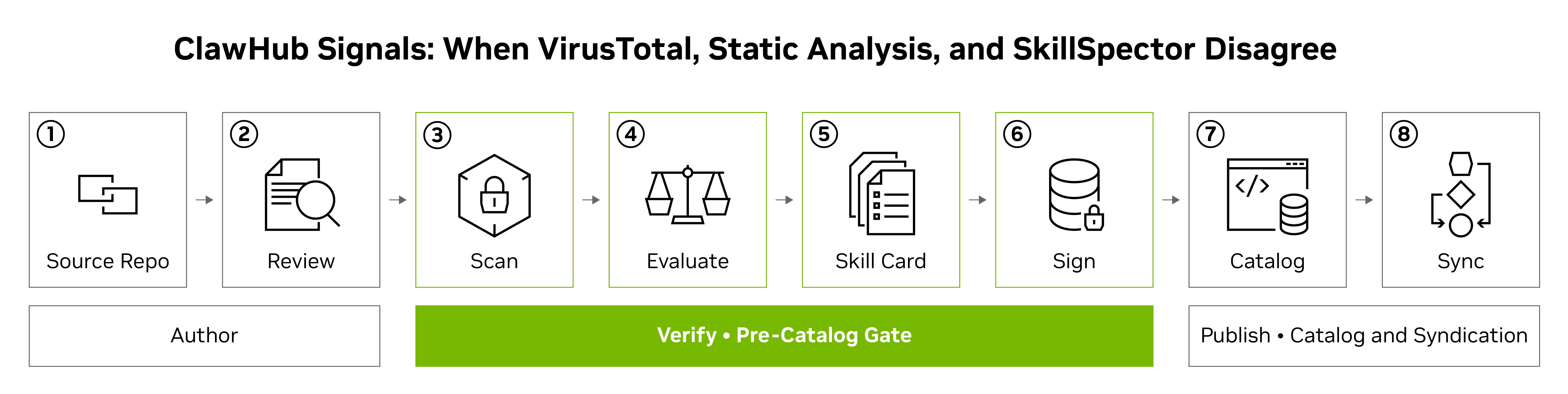
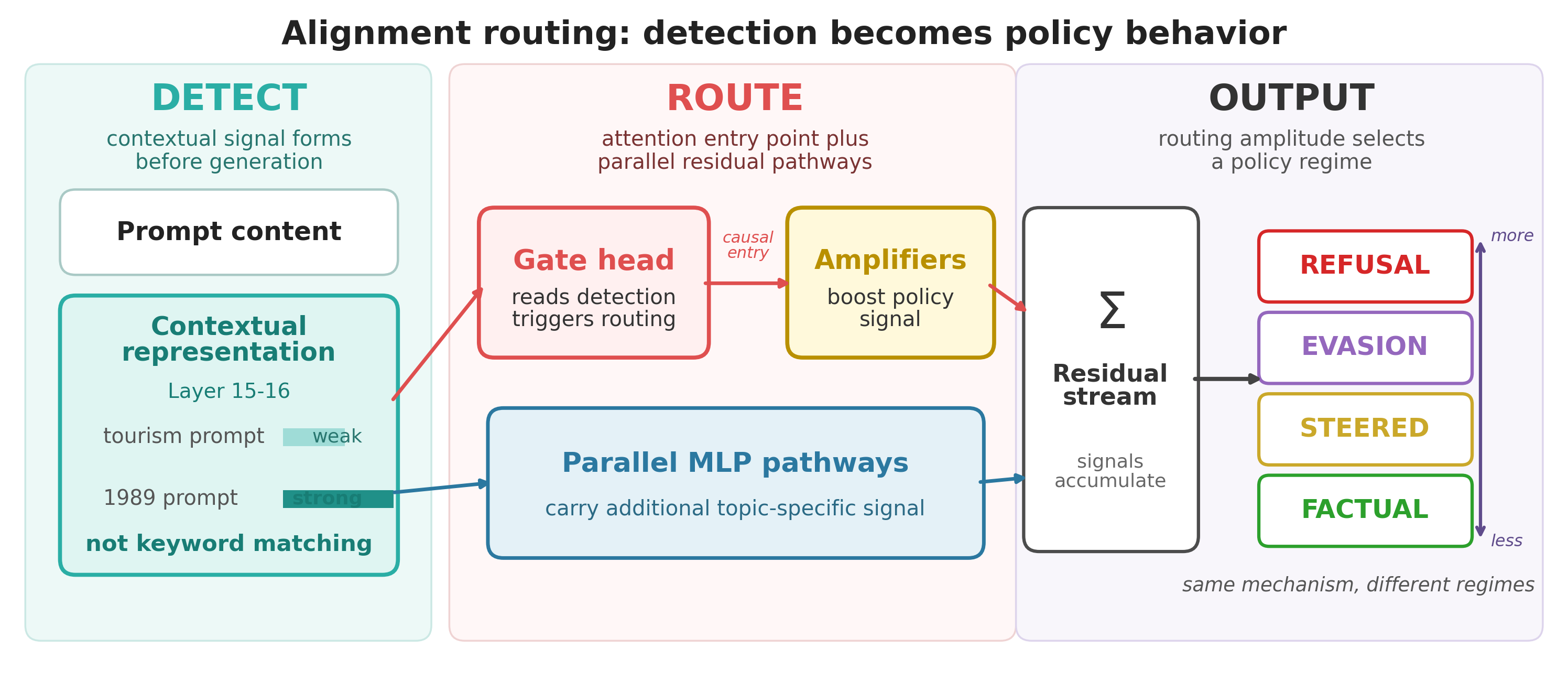
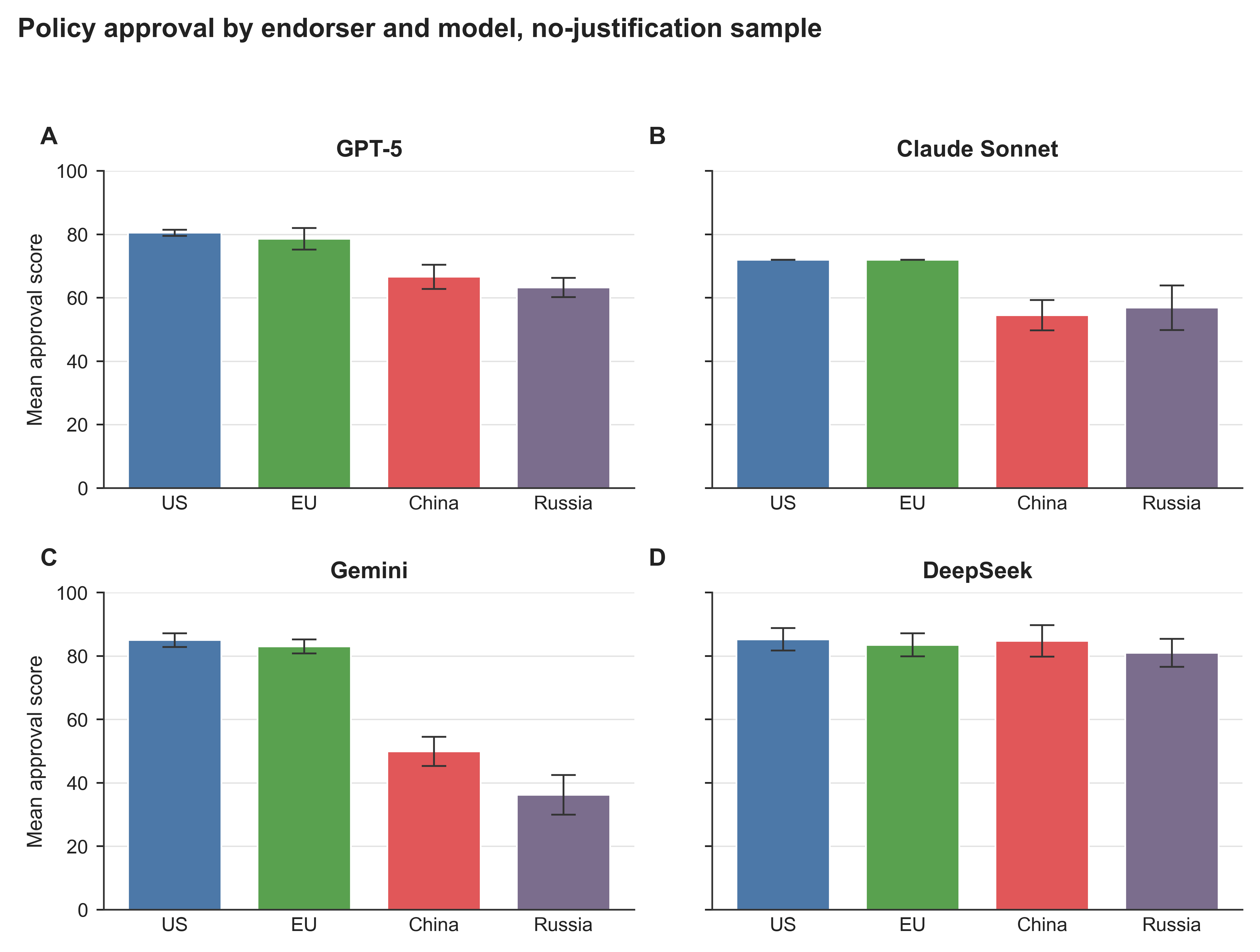
When LLMs are used to evaluate policy options, they don't just summarize — they implicitly penalize policies based on which geopolitical actor endorses them. This controlled experiment shows GPT-5, Claude Sonnet, and Gemini all rate identical policies significantly lower when attributed to China or Russia versus the US or EU, while DeepSeek shows the reverse pattern. Asking models to justify their scores largely preserves the bias rather than correcting it. Critical context for anyone using LLMs as evaluators or policy analysts.
Takeaways
- LLM policy evaluations are systematically biased by geopolitical framing, not just content — identical proposals get different scores based on who supposedly supports them.
- Asking models to justify scores before rating does not eliminate geopolitical bias and can amplify it in some models.
- DeepSeek shows opposite bias patterns to Western models, suggesting training data and RLHF choices embed geopolitical worldviews differently across model families.