Accessible
Appearing Productive in The Workplace — No One
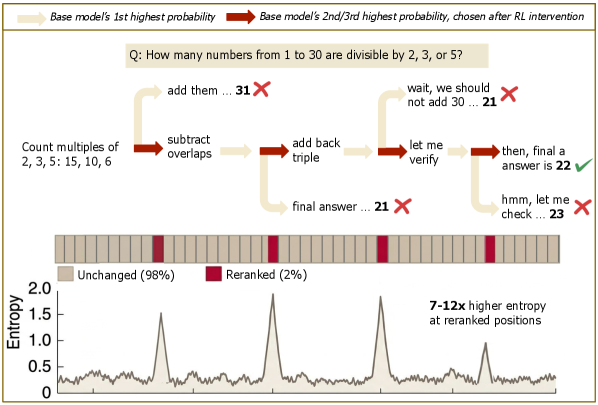
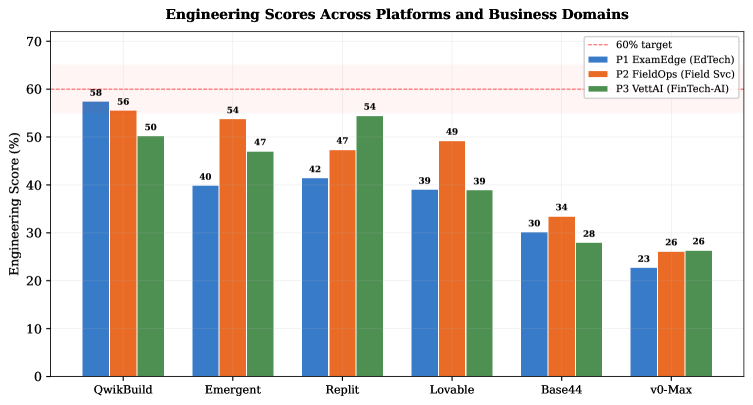
This challenges the conventional wisdom that AI-generated code is obviously detectable by experienced engineers. The author argues that AI can now produce work that passes expert review while containing fundamental flaws that only surface later in production, creating two dangerous failure modes: code that looks professional but lacks deep understanding, and teams that become dependent on AI output they can't properly evaluate.
Takeaways
- AI-generated work can fool experienced reviewers by appearing expert without actually being expert.
- The failure modes are both immediate (bad code getting through) and systemic (teams losing evaluation skills).
- Traditional code review processes may be insufficient for AI-assisted development.