Intermediate
Fine-Tuning for an Exam Quality Tutor
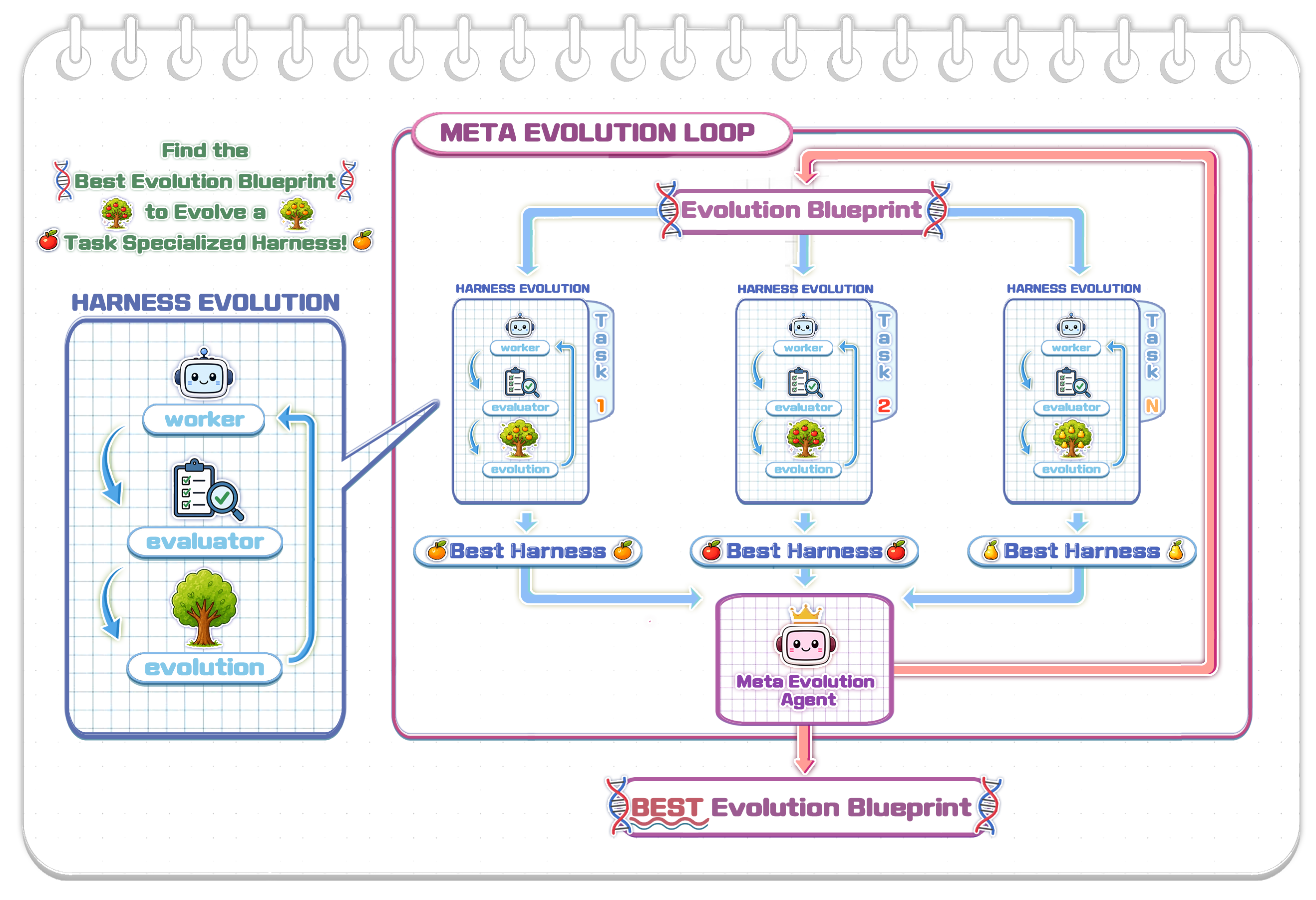
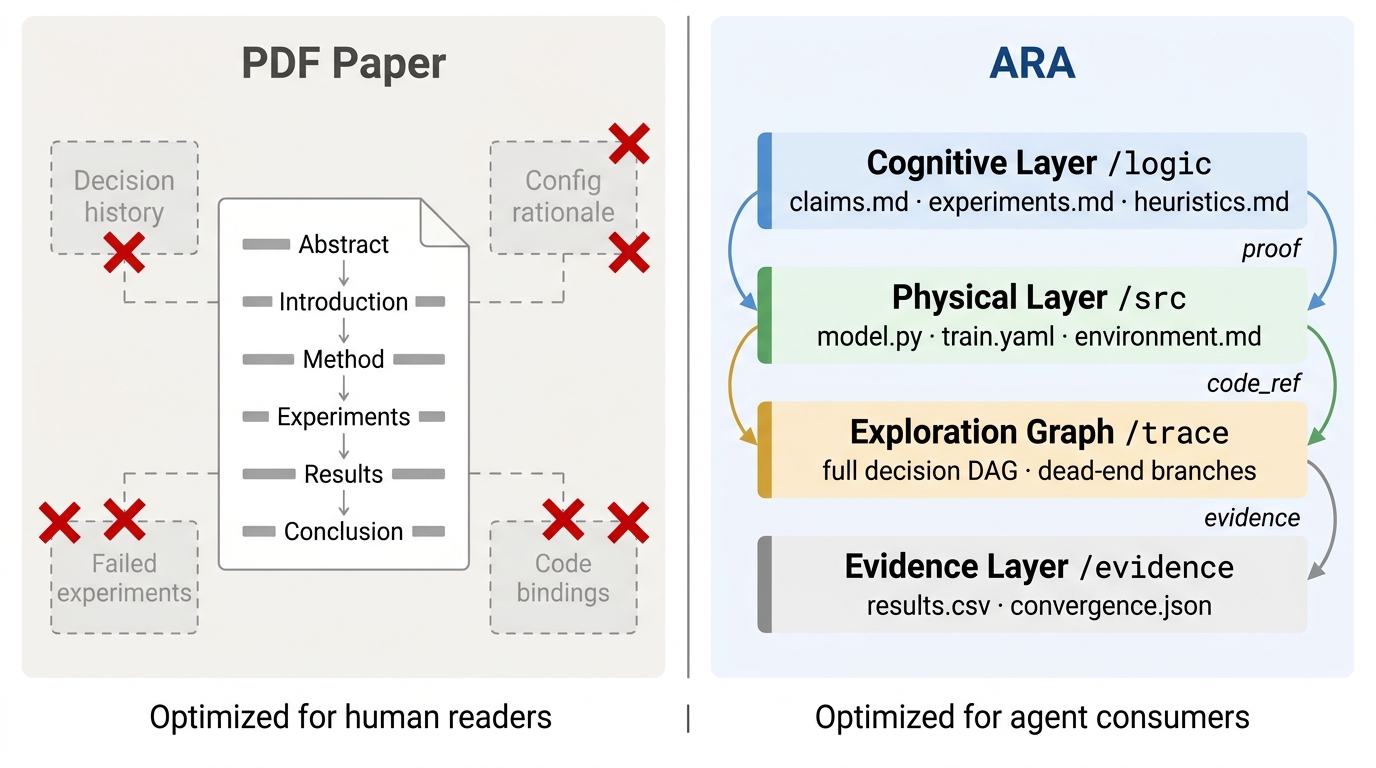
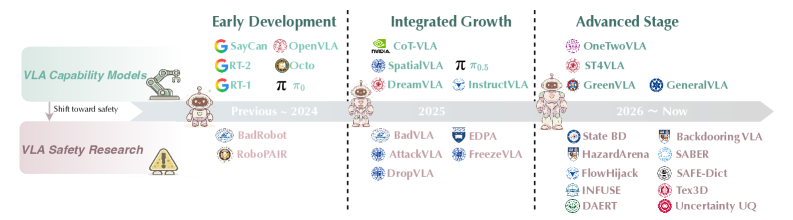
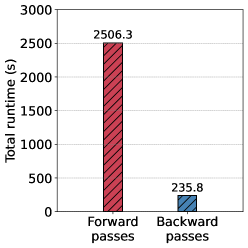
A hands-on exploration of fine-tuning a 27B parameter model for personalized learning that reveals the practical realities of adapting large models for specific use cases. This personal experiment offers valuable insights into the effort, infrastructure, and unexpected challenges you'll face when moving beyond API calls to custom model training.
Takeaways
- Fine-tuning large models for specialized tasks requires significant infrastructure planning and iteration cycles.
- The gap between theoretical fine-tuning approaches and practical implementation reality is substantial.
- Personal use cases can serve as effective testing grounds for understanding model customization challenges.