Intermediate
The AI engineering stack we built internally — on the platform we ship
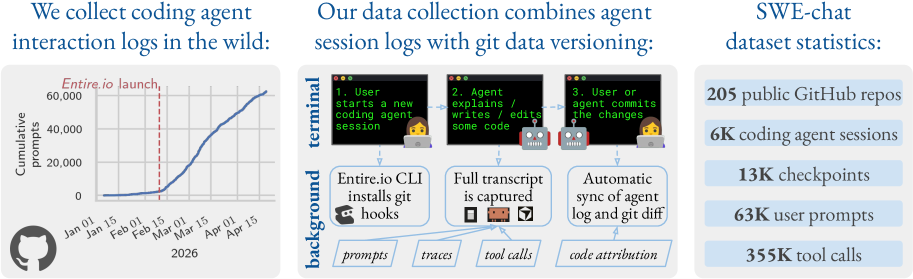
Cloudflare shares real metrics from running their own AI engineering stack in production, processing 241 billion tokens and serving 3,683 internal users. This is essential reading if you're building AI infrastructure — they dogfood their own products (AI Gateway, Workers AI) and provide actual numbers on throughput, costs, and architectural decisions. The post challenges the common wisdom of building separate dev/prod AI stacks by showing how running on your own platform reveals critical performance and scalability insights.
Takeaways
- Running AI infrastructure on the same platform you ship reveals hidden performance bottlenecks and helps prioritize product improvements.
- Processing 241 billion tokens across 20 million requests provides concrete scale benchmarks for AI Gateway architecture decisions.
- Dogfooding AI products with thousands of internal users uncovers real-world usage patterns that synthetic benchmarks miss.