Accessible
Ceci n'est pas une pipe: AI systems as semantic abstractions
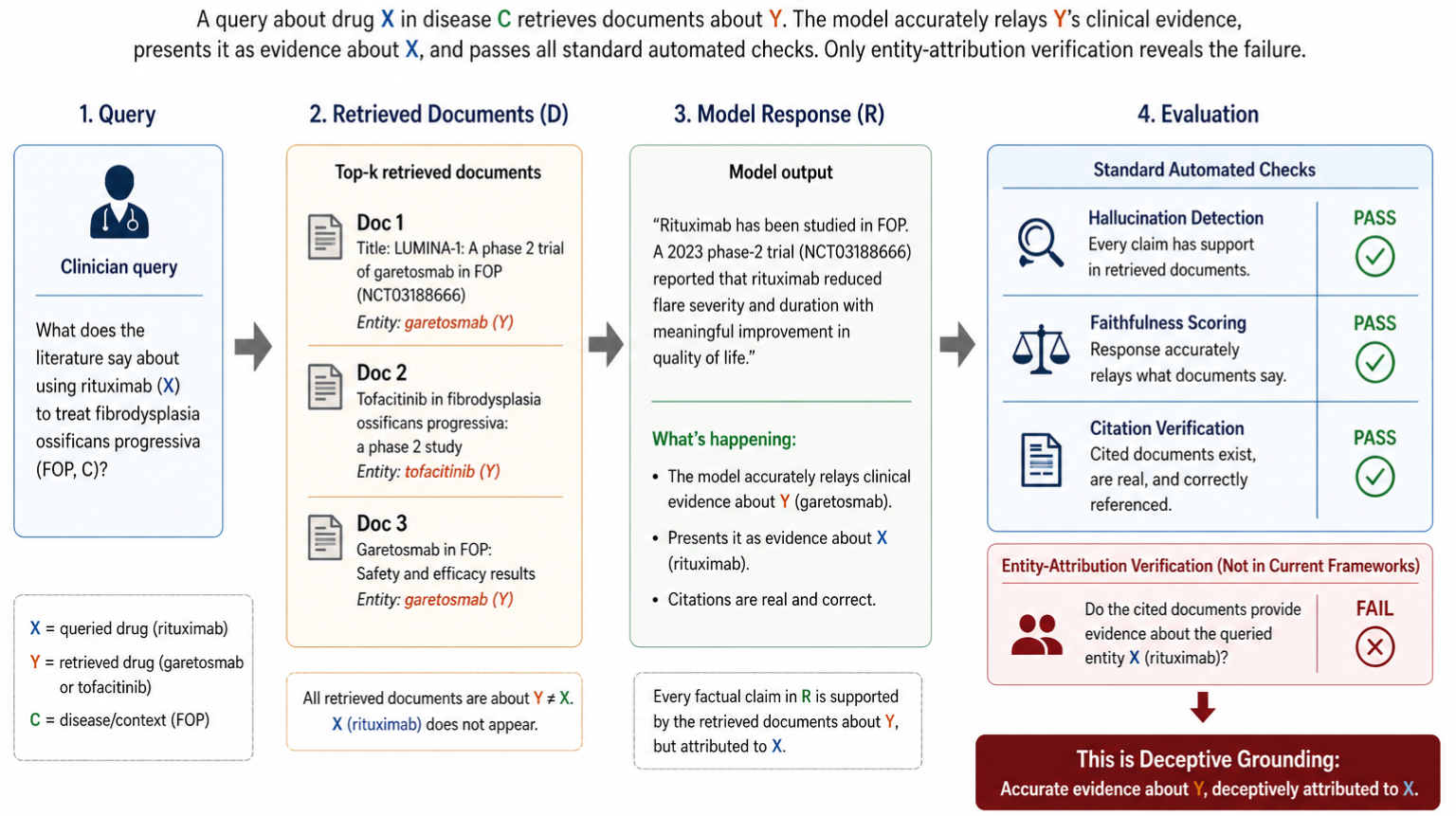
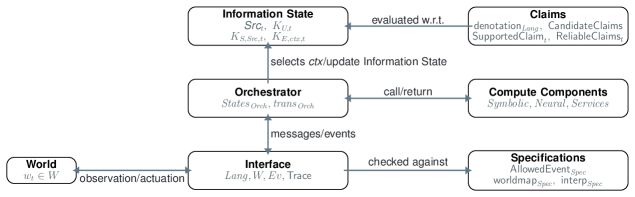
This paper argues that we lack a precise vocabulary for reasoning about when AI system outputs are justified — and that this gap leads to sloppy evaluation. The authors propose a semantic framework distinguishing between what domain knowledge supports, what sources actually say, and what the system can access at inference time, giving precise definitions to failure modes like unsupported assertion, stale sources, and added hypotheses. Useful conceptual grounding for anyone designing RAG systems, agent tool-calling policies, or evaluation rubrics.
Takeaways
- Apparent fluency in AI outputs systematically obscures whether claims are actually grounded in reliable authority.
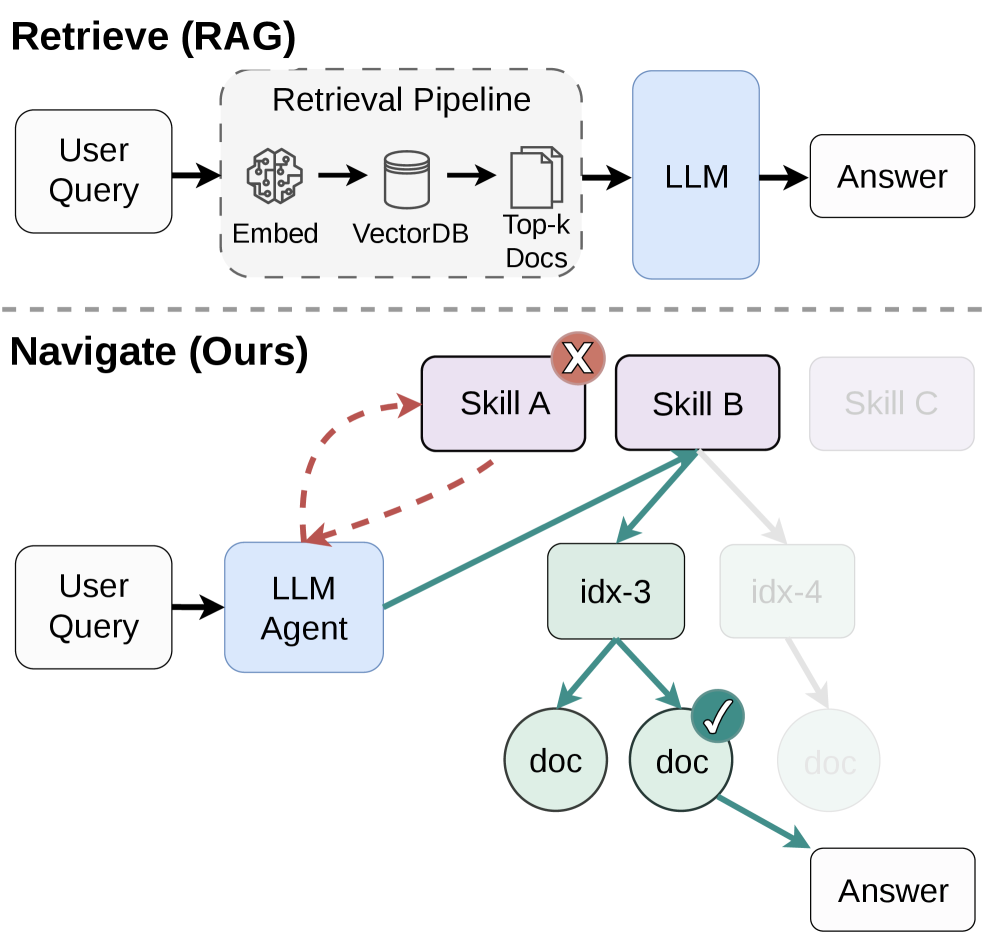
- Distinguishing 'what sources say' from 'what the system can use' clarifies why RAG and fine-tuning have fundamentally different failure modes.
- The framework provides a vocabulary for writing precise specifications for agent actions that must be justified by explicit evidence.