Advanced
Towards Mechanistically Understanding Why Memorized Knowledge Fails to Generalize in Large Language Model Finetuning
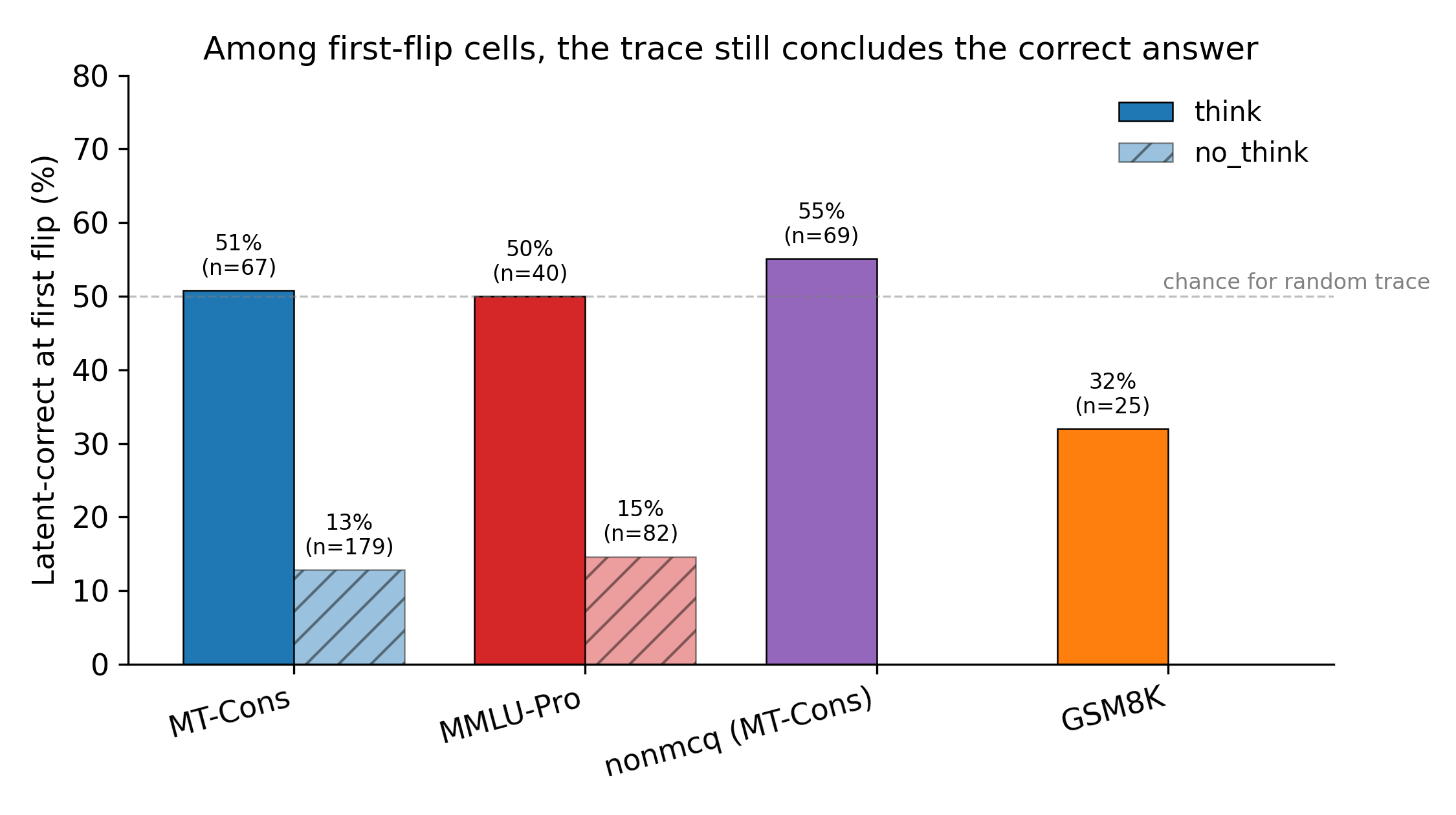
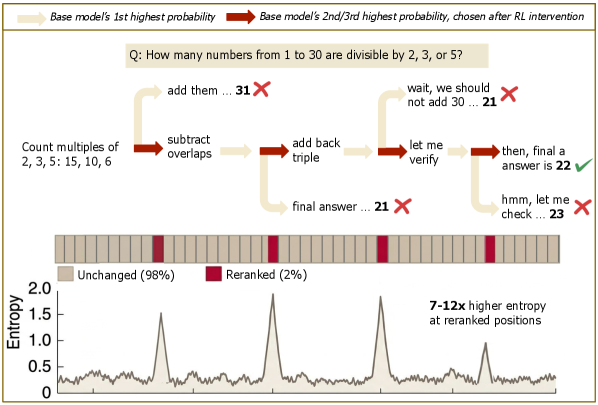
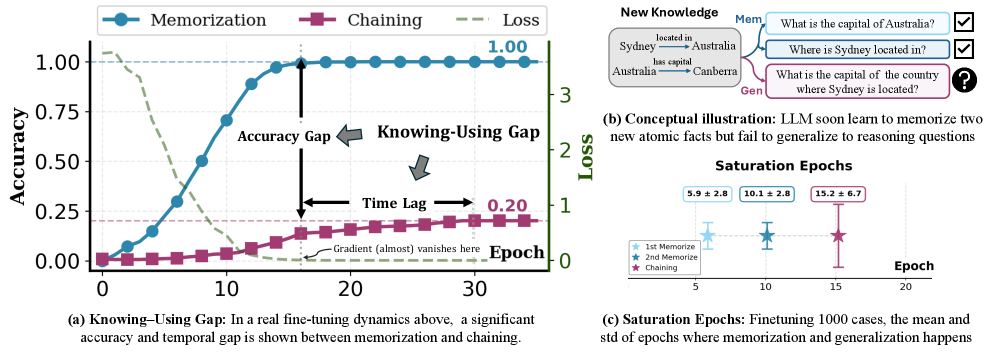
Fine-tuning to inject new knowledge into LLMs produces a frustrating pattern: the model memorizes the facts but fails to use them in downstream reasoning. This paper investigates the mechanism and finds that memorized representations often exist in the model but aren't routed through the layers where they'd actually influence computation — a 'knowledge-circuit misalignment.' The practical upshot is a diagnostic technique that recovers 58-75% of the generalization gap without architectural changes.
Takeaways
- Memorization and usable generalization are mechanistically distinct processes that fine-tuning can decouple.
- Knowledge-circuit misalignment means a model can 'know' a fact internally while completely failing to apply it during reasoning.
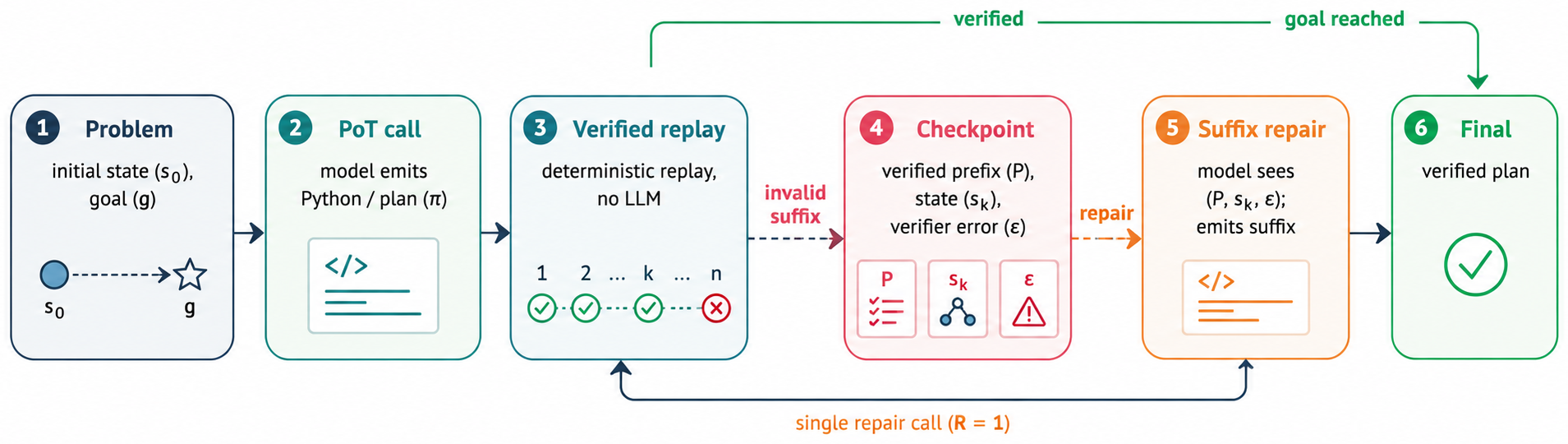
- Self-patching as a diagnostic technique can identify which layers need intervention without requiring full retraining.