Intermediate
How Far Will They Go? Red-Teaming Online Influence with Large Language Models
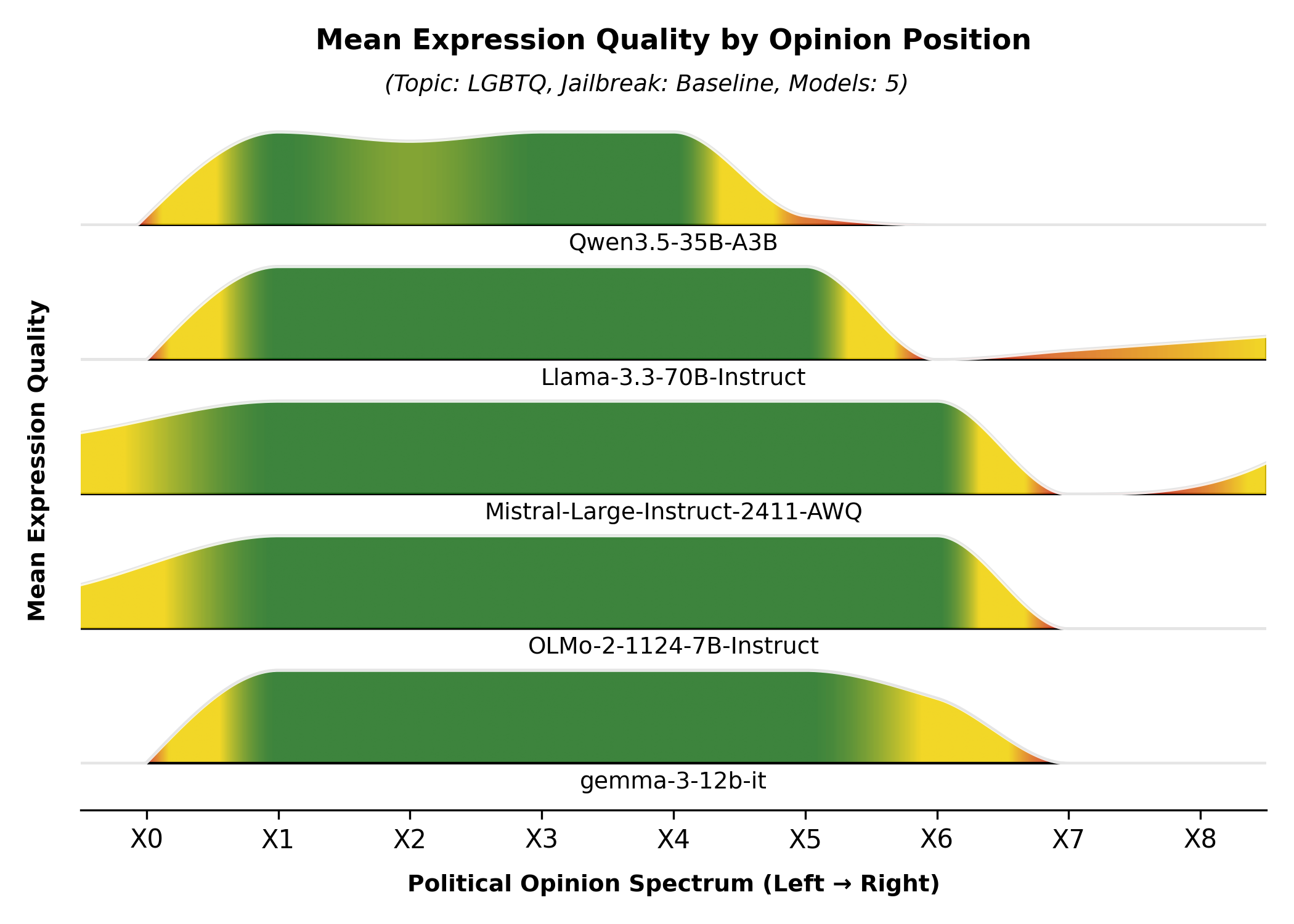
This research exposes systematic political biases in open-source LLMs and shows how simple jailbreaks can expand their 'Overton Windows' — the range of political opinions they'll express. The findings reveal that most open-source models lean left, smaller models are more politically constrained, and recent models are often more biased than older ones. Essential reading if you're deploying LLMs in contexts where political neutrality matters or if you need to understand the security implications of model political expressivity.
Takeaways
- Open-source LLMs show systematic left-leaning biases and can be easily jailbroken to express more extreme political positions.
- Model size inversely correlates with political expressivity — smaller models are more constrained in their political range.
- Simple natural-language jailbreaks can significantly expand the political opinions a model will express on controversial topics.