Intermediate
WebCompass: Towards Multimodal Web Coding Evaluation for Code Language Models
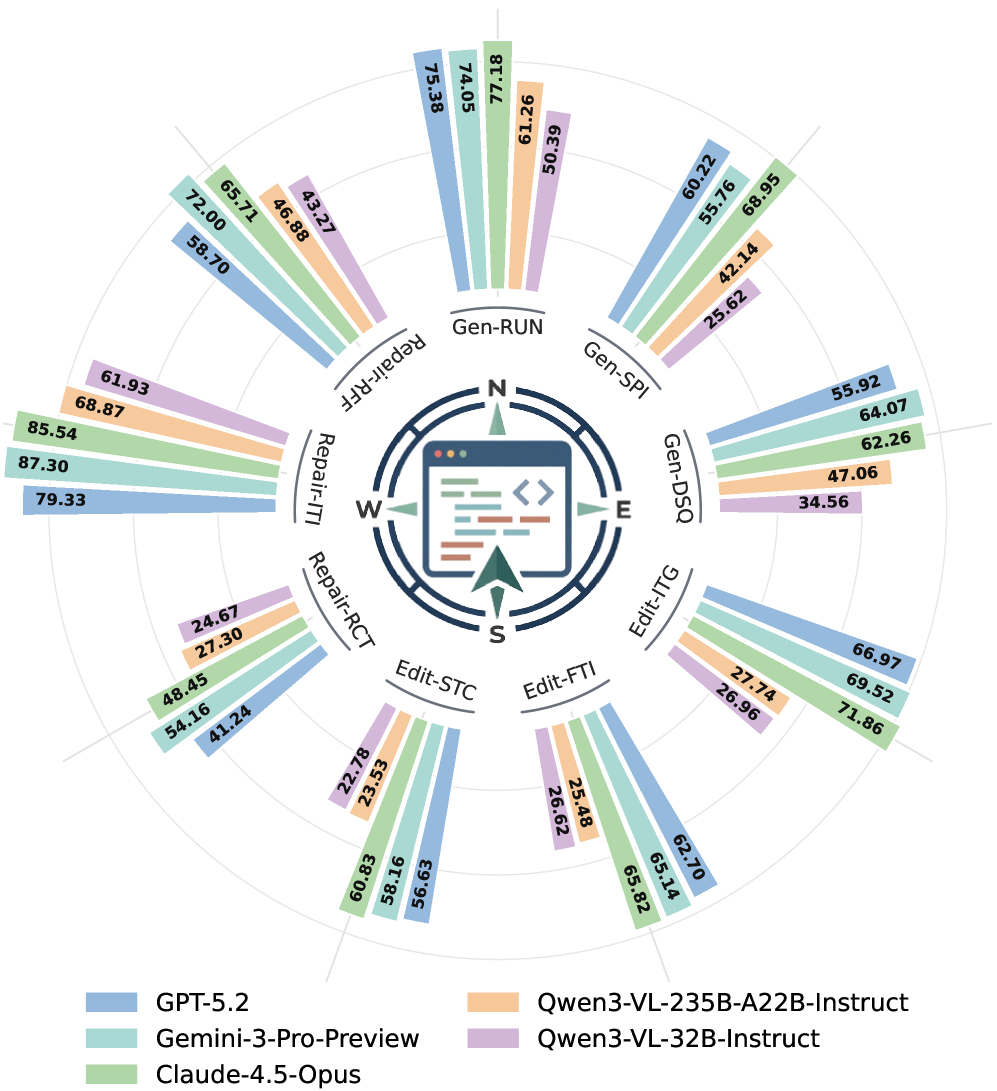
WebCompass introduces the first comprehensive benchmark for evaluating code language models on real web development workflows, spanning text, image, and video inputs across generation, editing, and repair tasks. This matters because existing benchmarks only test narrow slices of coding capability while missing visual fidelity and interaction quality — critical gaps if you're building or evaluating AI coding tools for web development.
Takeaways
- Current coding benchmarks fail to capture the full lifecycle of web development, missing visual fidelity and interaction quality.
- Real-world web coding requires multimodal understanding across text, image, and video inputs in iterative generation-editing-repair cycles.
- LLM-as-a-judge evaluation with checklist guidance provides a practical methodology for assessing complex web development outputs.